AI-Powered Image and Video Generation with ComfyUI
 Comfyui Project
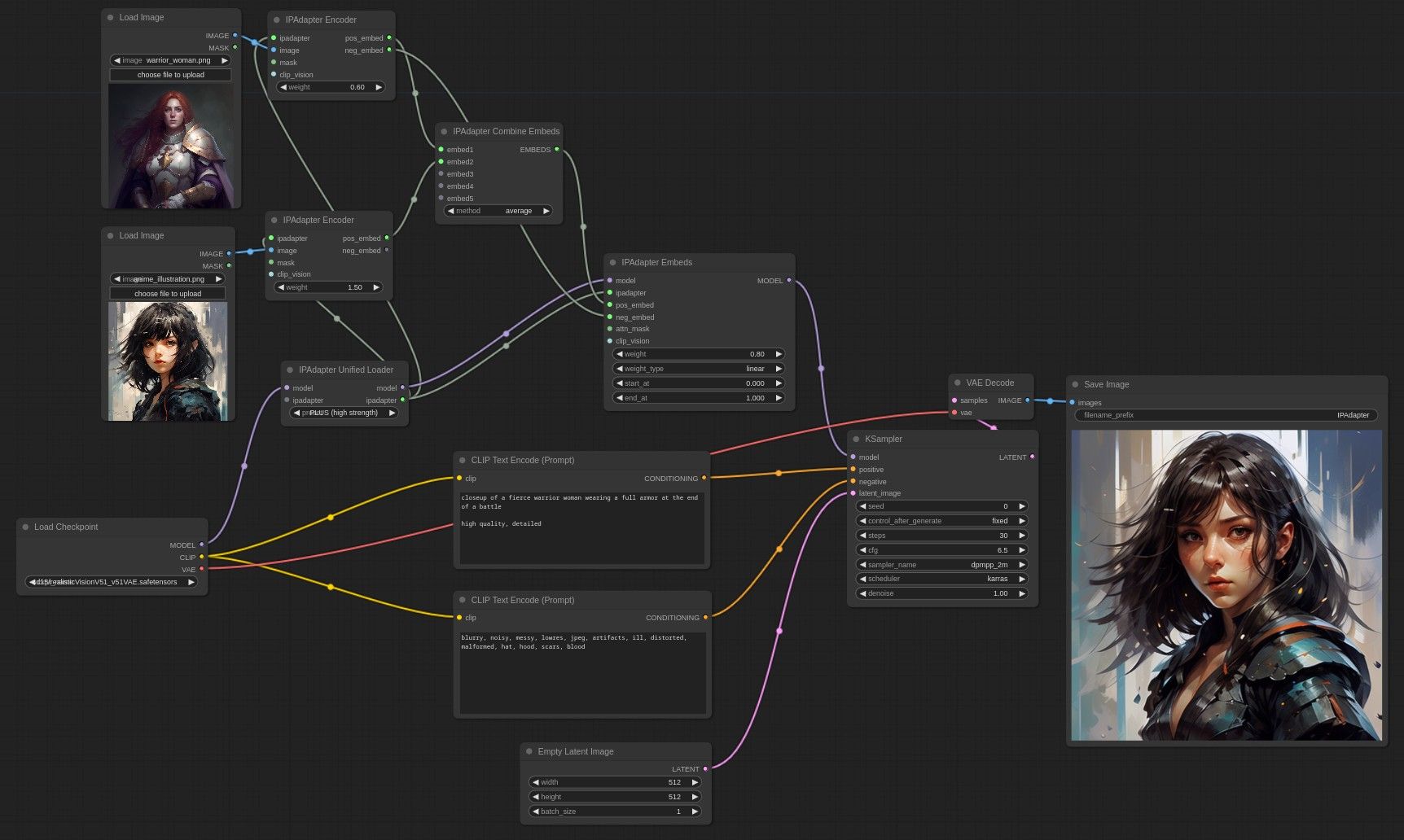
Comfyui Project
This project leverages the ComfyUI platform to explore and implement a variety of AI models for image and video generation. By integrating state-of-the-art generative models, e.g., Flux, Stable Diffusion, etc., the project aims to create a user-friendly workflow for producing high-quality visuals, enabling artists, developers, and enthusiasts to generate content effortlessly.
Key Features:
- Multi-Model Integration: Utilize a diverse set of AI models (e.g., Stable Diffusion, SDXL, ControlNet, and others) to generate both static images and dynamic videos.
- ComfyUI Workflow Optimization: Design modular and efficient workflows within ComfyUI to adapt usecases and enhance usability, customization, and scalability.
- Image Generation: Generate highly detailed and realistic images based on text prompts, sketches, and style-guided inputs.
- Video Generation: Implement AI-driven video synthesis methods, enabling smooth transitions, frame interpolation, and AI-powered animations.
- Customization & Control: Provide users with fine-tuned settings for resolution, style transfer, depth mapping, and more.
- Automation & Scripting: Enable batch processing, API integrations, and automation features for streamlined creative workflows.
Potential Use Cases:
- Digital Art & Design: Artists and designers can create unique visuals effortlessly.
- Video Content Creation: AI-powered video generation for animations, ads, and visual storytelling.
- Game & VR Development: Generate textures, assets, and immersive AI-driven content.
- Marketing & Branding: Businesses can create eye-catching media content for campaigns.
Jiawei Zheng
Postdoctoral Research Fellow
Jiawei Zheng’s research interests include AI, Data Science, Blockchain, Process Mining, and IoT.